Writing Normal Pipelines
This article focuses on the specifics of writing a Normal pipeline to process a set of as opposed to a Flow pipeline which runs many normal pipelines.
A Normal pipeline processes data from 1 or more sources as a single batch and loads that data into 1 or more tables. Each batch has an ID and every data record of every table that is loaded by that batch is linked to a specific batch ID.
First, read the introduction to pipelines article, which explains the basic concepts and steps to creating pipelines.
A simple pipeline
This is a simple pipeline which prompts the user to upload an Excel file, extracts data from a worksheet named “CASES”, and loads that data into a user-created table in xMart also named “CASES”. The name of the table while being processed by the pipeline is “data”.
<XmartPipeline>
<Extract>
<GetExcel TableName="CASES"
OutputTableName="data" />
</Extract>
<Load>
<LoadTable SourceTable="data"
TargetTable="CASES"
LoadStrategy="MERGE">
<ColumnMappings Auto="true" />
</LoadTable>
</Load>
</XmartPipeline>
The Extract section is required, which defines how data is extracted from data source(s) to be processed by the pipeline. Multiple “Get” commands can be listed here to extract multiple tables from multiple sources.
The Load section includes one or more LoadTable sections, which define how extracted data are loaded into xMart. Each LoadTable section corresponds to a single, particular xMart table. Multiple LoadTable sections can be present to load data into multiple tables.
Summary of each command property:

The LoadStrategy is an important concept in xMart pipelines:

ColumnMappings map source columns in a pipeline table to columns in xMart. Using Auto="true" saves time by automatically mapping columns that have the same name in the source as in xMart.

To manage differences in columns between origins, you can use Optional="true" and/or define a list of origin codes for which the column mapping is relevant.

Full pipeline structure
Pipeline structure showing every possible section:
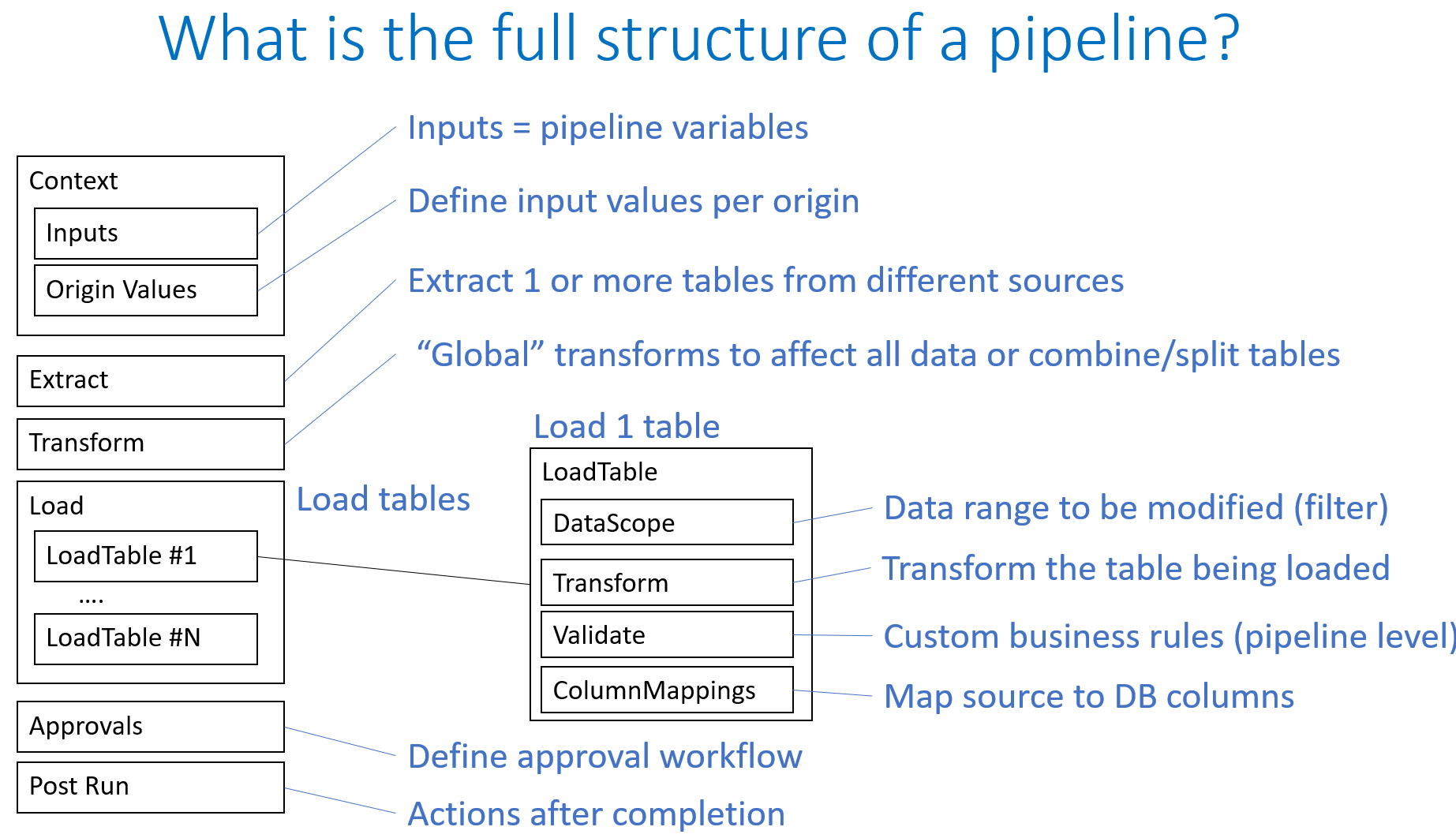
Context
Context is used to define Pipeline variables
Extract
Every pipeline must have an Extract section. This is used to put data into the pipeline.
Extract data from a file
When a pipeline is written to load a file, a file needs to be dragged on to the pipeline.
Currently, if the pipeline needs to load multiple files then it must use GetZip.
If the file could in more than one format (e.g. Excel or Text) then OneOnly can be used.
There are commands to support different file formats.
A full list of the file extracts can be found here
Extract data from an external source
Data can also be extracted from an external source such as a DBs, web services and FTP servers.
A full list of the extarnal source extracts can be found here
Special Cases
OneOnly
OneOnly allows a pipeline to support different file types (such as Excel, Access, csv, etc.) when the internal data structure is the same regardless of the type. For example, a user have a table in MS Access and then switch to Excel, while the table structure itself has not changed (same column names).
OneOnly
is a container element into which a list of Getter commands are placed. When a user uploads a file, the first applicable Getter in the list is used to extract the file. If no applicable Getter is found, the load fails.
GetZip
GetZip extracts data from files stored in a zip file uploaded by the user or fetched via GetWebService. The files can be of different formats
Excel,
Text,
Json and
Recfile
It can be used multiple times to extract different files from the same zip. This means that if more then one file is being loaded, this is the command to use.
Transform
There are two transform sections. One is in the main pipeline before the Load section abd one is within the LoadTable section.
The Transform in the main pipeline has all of the tables available to it so it is the place to perform operations such as CopyTable, JoinTables and MergeTables.
There are many global changes which users may want to perform on all of the data such as standardising the dates using FormatDate, renaming columns using either RenameColumn or RenameColumnsByLookup
The Transform in the LoadTable section can only perform operations on the Source table of the LoadTable. It can look up values in other tables but cannot change them.
A full list of transforms can be found here
Load/LoadTable
Each pipeline that loads data into tables must have a load section.
Load Auto
The Load has a parameter called “Auto” which can be set to OFF (default), MERGE, REPLACE or APPEND. If it is set to any value other than OFF then it introduces a new, dynamic way of creating LoadTable sections for any tables which are read in and do not have a LoadTable section. It is based on the names of the in-memory tables, which must match the target table names and the column names in the in-memory table which must match as well.
So this pipeline
<XmartPipeline>
<Extract>
<GetExcel TableName="CASES"
OutputTableName="data" />
</Extract>
<Load>
<LoadTable SourceTable="data"
TargetTable="CASES"
LoadStrategy="MERGE">
<ColumnMappings Auto="true" />
</LoadTable>
</Load>
</XmartPipeline>
could be replaced by
<XmartPipeline>
<Extract>
<GetExcel TableName="CASES"
OutputTableName="cases" />
</Extract>
<Load Auto="MERGE" />
</XmartPipeline>
LoadTable
If Load Auto isn’t set, or is set to OFF a LoadTable section is needed for each table that needs to be loaded. They can also be included if the Load Auto value is set. In this case, the LoadTable section provided is used rather than the automatically generated one.
Restricting which data can be modified (DataScope)
Data in a LoadTable section can be restricted using a DataScope. This is a filter defined in a LoadTable section and applied to both the source data (in your file) and the target data (in the DB). It defines the range or “scope” of the data to be modified. It prevents data outside of this range from being modified.
It can be used with either REPLACE or MERGE.
Here is an example.
<Load>
<LoadTable SourceTable="Data" TargetTable="FACT_DEMAND" LoadStrategy="REPLACE">
<DataScope Operator="AND">
<Terms>
<Term Operator="OR" Field="SOURCE_FILE_FK" Rule="LikeExactly">
<Value>UNDP</Value>
</Term>
</Terms>
</DataScope>
<Transform >
<AddColumn Name="SOURCE_CODE" FillWith="UNDP" />
A DataScope filter is a list of filter “terms”. Most people only need a single term. If you have multiple terms, they are “AND”ed by default (that’s Operator=”AND” on the DataScope line below). It’s like a search form in a user interface – each part of the search form is ANDed.
Inside of each term supports 1 or multiple values. Multiple values inside of a term are “OR”ed by default (that’s Operator=”OR” on the Term line below). This is like selecting multiple options in a dropdown on a search form – each item (like multiple countries or years) are ORed.
If you want multiple values to be ORed, list multiple values. This will filter on data where SOURCE_FILE_FK is either UNDP, UNICEF or GAVI.
<Load>
<LoadTable SourceTable="Data" TargetTable="FACT_DEMAND" LoadStrategy="REPLACE">
<DataScope Operator="AND">
<Terms>
<Term Operator="OR" Field="SOURCE_FILE_FK" Rule="LikeExactly">
<Value>UNDP</Value>
<Value>UNICEF</Value>
<Value>GAVI</Value>
</Term>
</Terms>
</DataScope>
<Transform >
Records that are outside of Datascope are highlighted in the data preview as “Outside of DataScope”
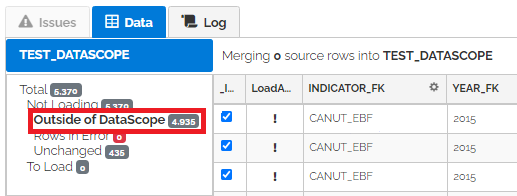
It is possible to use batch input variables in DataScope filters. This way filters can be customized per origin for the same pipeline. Since batch input variables can be set by prompting the user at the time of upload, the person uploading can also set the filter at the time of upload. In the following example a batch input variable “${SurveyCode}” is used to filter a SURVEY_FK value.
<Load>
<LoadTable SourceTable="interviews" TargetTable="RAW_2019_INTERVIEWS" LoadStrategy="REPLACE">
<DataScope Operator="AND">
<Terms>
<Term Operator="OR" Field="SURVEY_FK" Rule="LikeExactly">
<Value>${SurveyCode}</Value>
</Term>
</Terms>
</DataScope>
Validate
Validation is used to check values in rows. The validations are
| Validation | Purpose |
|---|---|
| TestColumnsExist | Verifies that a list of columns exists in the table |
| TestNotEmpty | Tests for the existence of required values |
| TestPattern | Verifies that a value matches a regular expression pattern |
| TestRow | Checks that a row is valid based on either matching a filter expression |
| TestValueInRange | Checks that a value is above, below or within a certain range of limits |
LookupIds
In order to resolve Foreign Key lookups, the input value needs to be looked up in the reference table. If the ColumnMapping Auto=”true” isn’t set or if the reference table has more than one BPK field, a pipeline will need to perform one or more SysIDLookup command.
ColumnMappings
The ColumnMapping section is used to connect the source table columns with the target table columns. There is an option Auto=”true” which will not only map the columns with the same name but will also perform any Foreign Key lookups if the source column name has the same name as the target column and the source column has a value in it which is the row title of the reference table.
Approvals
Batch approvals are used so that a data owner can check the data being loaded. More information and how to set up approvals is available in the Approve Batch article
PostRun
POstRun allows the pipeline to run another pipeline, call a web service or run a flow after the completion of the current pipeline. It resembles a Flow Pipeline
The commands are
| Command | Purpose |
|---|---|
| PostRun | Describe a flow of postRun commands to run after the initial pipeline batch completes |
| CallWebService | Calls a remote Web service API after a batch completes |
| Flow | Pipeline flow section: configure RunPipeline or CallWebService launch order from a single place. For more details see the article on Flow Pipelines |
| RunPipeline | Automatically triggers the run of a pipeline after the current Load is finished |
DB-Only Pipelines
A DB-only pipeline is a special type of pipeline which exclusively operates in the xMart database and is recommended for materializing a slow custom SQL view into a fast physical table.
Typically, pipelines process unstructured data outside of the database (ie in the web application) before being sent to the database. A DB-only pipeline only uses SQL statements that are executed on the database and is useful when there is only a need to move data already in an xMart table or view into another xMart table. The data is assumed to be structured and have perfectly correct data types.
DB-only pipelines are very efficient at materialization but the price is some pipeline features are not available, especially transforms.
How to make a DB-only pipeline
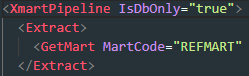
To make a DB-only pipeline, add IsDbOnly=”true” to the XmartPipeline element at the top:
Unsupported pipeline features
Pipeline elements that are not supported when IsDbOnly == true:
-
Any extract command other than GetMart.
-
Transform (both global and in Load). No transforms supported.
-
LoadTable/LookupIds. No foreign key lookups supported, but if the source object is a custom SQL view you can put you lookups there (ie use JOIN).
-
LoadTable/Validate
-
Batch Preview Page: Mostly the same but there limited issue reporting. Final commit is attempted but may fail without detail. There is no validation of each value which normally happens in the web server.
Supported pipeline features
- Context and origin input variables
- Batch variables
- REPLACE and MERGE strategies
- Approvals
- DataScope
- PostRun
- Batch preview still reports on NEW, UPDATED, UNCHANGED, etc.